
Wenn es zur Katastrophe kommt … oder was passiert, wenn ein SaaS-Anbieter insolvent wird?

Es begann an einem ganz normalen Donnerstagmorgen mit den üblichen Aufgaben im Bereich Netzwerk und Sicherheit. Während Raphi zu Hause seine erste Tasse Kaffee trank, lief alles routinemässig ab. Dann plötzlich: „Pling!“ Eine weitere Nachricht – doch diesmal anders als erwartet. Schnell wurde Raphi klar, dass er das Wochenende mit einem Krisenszenario auf höchster Eskalationsstufe verbringen würde.

Abbildung 1: E-Mail eines Anbieters, in der die Situation beschrieben wird.
Als Systems Engineer bei Open Systems brachte Raphi mehr als ein Jahrzehnt Erfahrung mit. Daher wusste er, dass der Produktmanager nicht übertrieb, als er ihn als Leiter des Krisenreaktionsteams vorschlug. Die E-Mail des Partneranbieters kam völlig unerwartet, ohne jegliche Vorwarnung. Darin hiess es, dass das Unternehmen den Grossteil seines Personals entlassen hatte und niemanden mehr für den Support seines Produkts bereitstellen konnte. Um diese Nachricht richtig einzuordnen, sollte man wissen, dass sich Open Systems darauf spezialisiert hat, Nutzer hybrider Umgebungen einfach und effizient zu vernetzen – und sie zugleich vor Bedrohungen zu schützen. 24×7. Weltweit.
Die Operations Center von Open Systems, bekannt unter dem Namen „Mission Control“, verwalten rund 10’000 Edge-Geräte in über 180 Ländern. Sie betreiben rund um die Uhr zuverlässig Web Proxys, Spam- und Malware-Filter, VPN-Tunnel, Firewalls, Konnektivität, Routing- und Netzwerkoptimierung, Verschlüsselung sowie Bedrohungsschutz – und das in hochverfügbaren Set-ups für globale Unternehmen. Um diesen Standard zu halten, arbeiten erfahrene Level-3-Ingenieure von Mission Control aus der Schweiz, Indien und Hawaii. So sind sie in allen Zeitzonen für ihre Kunden erreichbar. Jede Woche verbringen sie etwa einen Tag direkt in der Kundenbetreuung, während sie die restliche Zeit darauf verwenden, Netzwerke und Systeme weiterzuentwickeln, zu warten und zu optimieren – mit dem klaren Ziel maximaler Leistungsfähigkeit. Sicherheit ist dabei in jede Handgriff integriert.
Chaos strukturieren
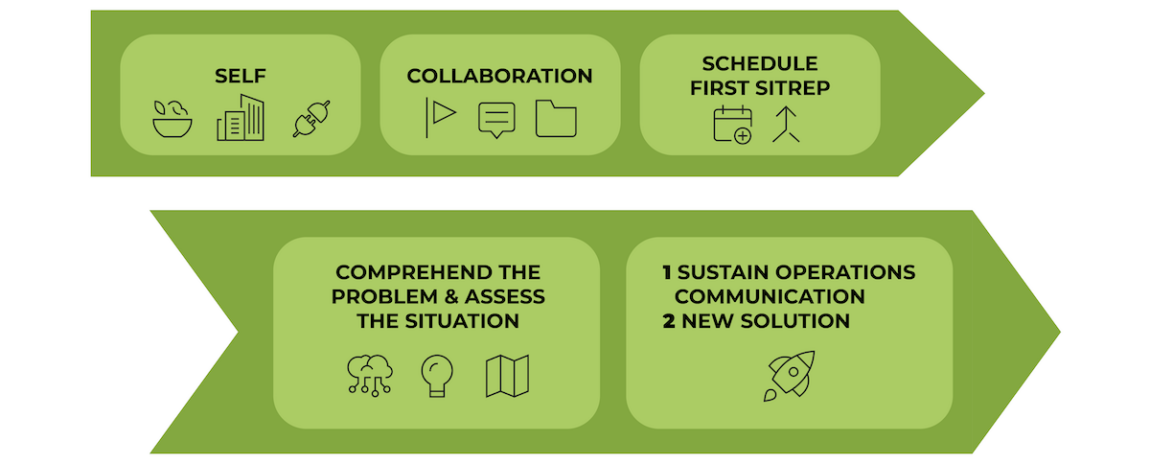
Abbildung 2: Erste Schritte, um Ordnung ins Chaos zu bringen.
Im Büro reservierte Raphi einen Besprechungsraum als Einsatzzentrale. Danach richtete er einen dedizierten Kommunikationskanal ein und erstellte eine Struktur zur Dokumentation, in der sein Team später seine Erkenntnisse festhalten konnte. Das erste SITREP-Meeting (Lagebericht) würde wichtig sein, um eine schnelle Abstimmung zu ermöglichen und koordinierte Massnahmen einzuleiten. Doch zuvor lag es an ihm, die Situation klar und prägnant zu beschreiben.
Und einen Plan zu entwickeln.
Er notierte die Fakten:
- Anbieter – insolvent.
- Produkt des Anbieters wird im Proxy-Service verwendet.
- Produkt funktioniert noch, aber wenn es ausfällt, wird sich die Lage verschärfen.
- Wochenende steht vor der Tür.
Er erkannte, dass er 3 Dinge anpacken musste:
- Den Betrieb aufrechterhalten und gleichzeitig transparent mit den Kunden kommunizieren.
- Eine neue Lösung erarbeiten.
Dann konnte es an die Umsetzung gehen.
Innerhalb der ersten Stunden nach dem ersten SITREP-Meeting wurde die erste koordinierte Reaktion gestartet.
Erster Tag
Raphi konnte sich darauf konzentrieren, einen groben Plan zur Bewältigung der Situation zu erstellen. Besonders wichtig war ihm, nicht ins Mikromanagement abzurutschen.
High-Level-Plan
Sein Plan musste für alle Beteiligten verständlich sein: Kunden, Führungskräfte, Ingenieure, Account Manager und alle, die am Betrieb oder Mission Control beteiligt waren.
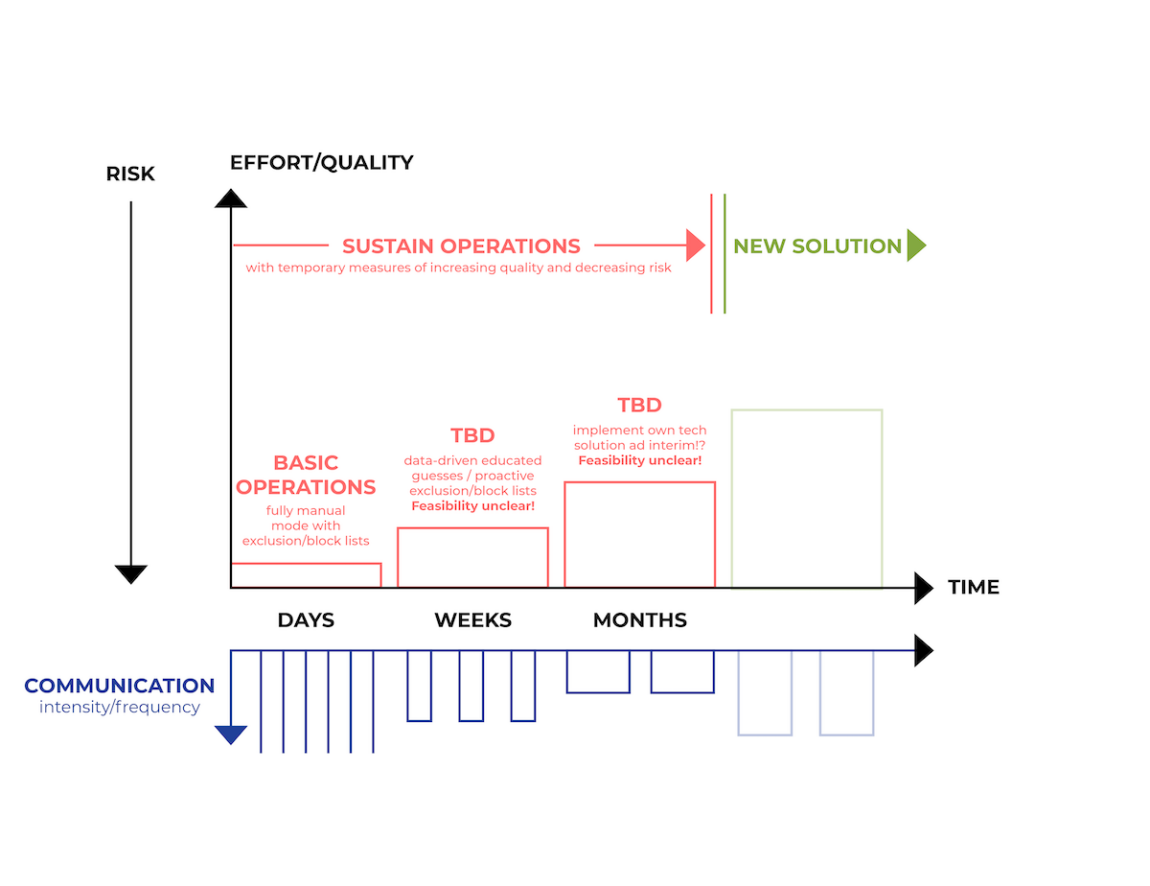
Abbildung 3: High-Level-Plan, illustriert von Raphi.
Der Plan sah vor, dass das Unternehmen in den ersten Tagen, Wochen und Monaten den Betrieb aufrechterhalten musste. Chris, ein Ingenieur des Web-Security-Teams, wurde damit beauftragt. Eine neue Lösung unter der Leitung eines anderen Open-Systems-Ingenieurs würde realistischerweise erst in einigen Monaten verfügbar sein. Bis dahin mussten häufige, aber kurze Updates kommuniziert werden, die mit der Zeit seltener werden konnten.
Kommunikation
Das Team setzte auf eine schnelle und transparente Kommunikation, ohne die Lage zu beschönigen. Innerhalb der ersten 24 Stunden erfolgte die Kundenkommunikation über E-Mails, Nachrichten im Kundenportal und Telefonanrufe. Im Hintergrund arbeitete Raphi währenddessen an einem detaillierten Aktionsplan.
Abbildung 4: Interne und externe Kommunikation war entscheidend.
Fehlermodi
Um den Betrieb in dieser frühen Phase aufrechtzuerhalten, musste Chris allen Beteiligten die technische Struktur erklären. Nur wenn alle die betroffenen Komponenten verstanden, liess sich eine zielführende Lösung erarbeiten.
Funktionsweise der betroffenen Komponenten
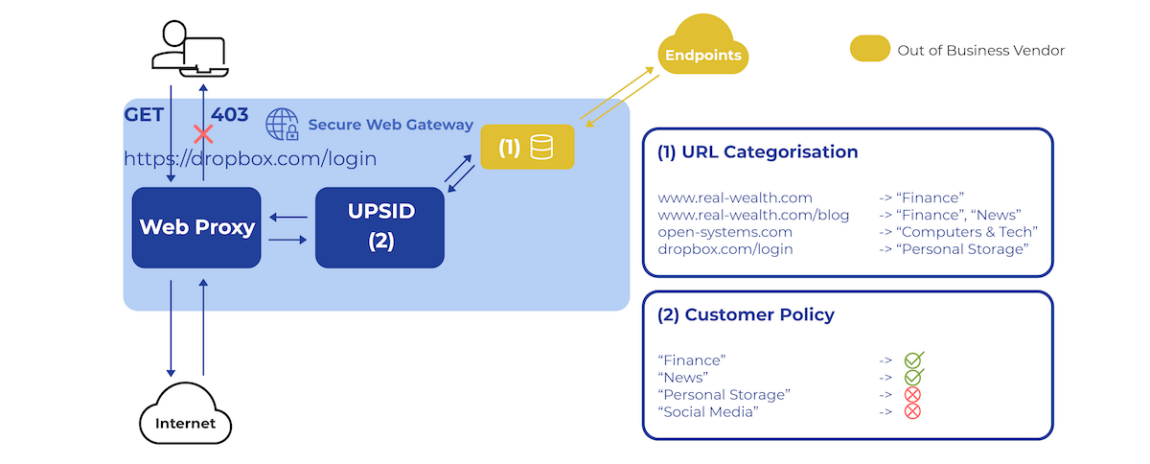
Abbildung 5: Diagramm der betroffenen Komponenten.
Das Secure Web Gateway (SWG) von Open Systems sichert den Web-Traffic von Kunden auf dem Weg ins Internet. Verschiedene Feeds in SWG analysieren den Traffic auf Bedrohungen oder verwenden den URL-Filter, um den Traffic zu klassifizieren – ein Service, der vom nun insolventen Anbieter bereitgestellt wurde.
Der URL-Filter bestand aus zwei Hauptkomponenten: einem lokal installierten Daemon und mehreren Cloud-Endpunkten des Anbieters.
Solange der Web-Traffic durch das SWG lief (siehe Abbildung 5), weist der URL-Filter der URL-Anfrage in einem ersten Schritt eine Kategorie zu – z. B. Finance, Personal Storage oder News. Der Daemon prüfte dann, ob die Kategorie bereits im lokalen Cache gespeichert war. Falls nicht, wurde die Anfrage an die Cloud-Endpunkte weitergeleitet.
In einem zweiten Schritt entschied der URL-Filter basierend auf unternehmensspezifischen Richtlinien, ob der Zugriff erlaubt oder blockiert wurde – beispielsweise „allow News, but block Personal Storage websites.“
Da die Systeme des Anbieters noch in Betrieb waren, wusste Chris, dass es wichtig war, potenzielle Fehlermodi zu identifizieren und zu beheben. Für ihn stand fest: Ein Systemausfall war unvermeidlich. Die entscheidenden Fragen waren: Wann und wie?
Analyseaspekte: (1) Qualitätsverschlechterung und (2) Daemon-Ausfall
Zunächst untersuchte sein Team
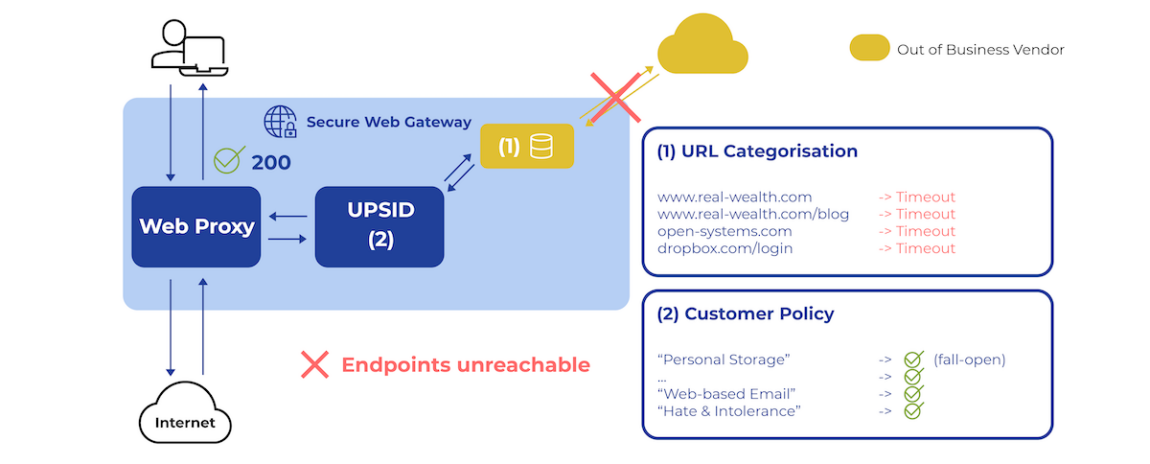
Abbildung 6: Zwei Fehlermodi der bestehenden Lösung.
Der zweite Fehlermodus, den es zu berücksichtigen galt, lautete: Was, wenn die Cloud-Endpunkte des Anbieters vollständig offline gingen?
Um dieses Szenario zu simulieren, setzte das Team von Chris lokale Firewall-Regeln auf ihrem Test-SWG ein. Die Vermutung bestätigte sich: Der proprietäre Daemon nutzte einen Cache und konnte den Betrieb für eine begrenzte Zeit aufrechterhalten. Letztendlich führten jedoch alle Klassifizierungsanfragen zu einem Timeout.
Open Systems hatte den URL-Filter bewusst im Modus „Fail Open“ konfiguriert, um sicherzustellen, dass das System im Falle eines teilweisen Ausfalls weiterlief. Allerdings bedeutete dies in diesem Fall, dass das SWG in einen „Allow All“-Zustand wechselte, weil Unternehmensrichtlinien nicht mehr angewendet werden konnten.
Eine bemerkenswerte Entdeckung des Teams: Jeder Versuch, den proprietären Daemon neu zu starten, scheiterte, sobald die Cloud-Endpunkte offline waren. Der Anbieter hatte eine Lizenzvalidierung implementiert, die eine aktive Verbindung zu den Cloud-Endpunkten erforderte – ein klassischer Designfehler.
Nachdem die beiden Ausfallmodi identifiziert waren, stand die interne Kommunikation an. Das Team von Chris erstellte ein Runbook, um die Ingenieure von Mission Control auf alle Eventualitäten vorzubereiten.
Sowohl Chris als auch Raphi blickten erleichtert auf einen intensiven ersten Tag zurück:
- Koordinierte Krisenreaktion ✅
- Technische Bewertung ✅
- Kommunikation ✅
Erste Woche
Um den Betrieb am Laufen zu halten, beschlossen die Ingenieure von Open Systems, die Funktionalität des URL-Anbieters vorübergehend zu imitieren. Dies würde dem SWG-Produktmanager die nötige Zeit verschaffen, eine langfristige Lösung für den Austausch der URL-Filter-Komponenten zu evaluieren.
Technischer Betrieb
Das Team von Chris entwickelte eine eigene lokale URL-Filter-Feed-Lösung (siehe Abbildung 7). Diese wurde in UPSID, den Sicherheits- und Richtlinien-Daemon, integriert, der die Klassifizierung übernahm, falls die Anbieter-Endpunkte unerwartet offline gingen.
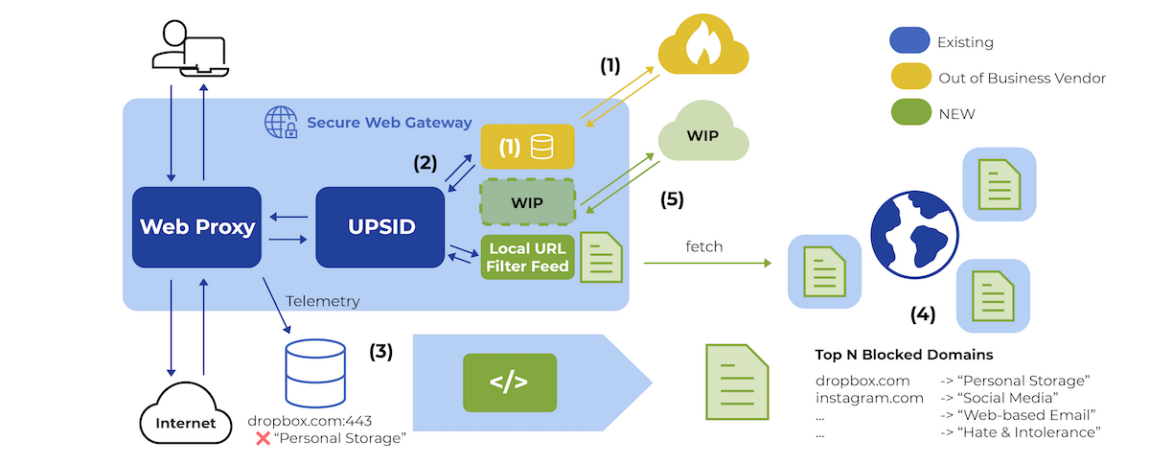
Abbildung 7: Erstellen eines temporären lokalen URL-Filter-Feeds.
Aus Sicherheits- und Compliance-Sicht ist es entscheidend zu wissen, welcher Traffic blockiert werden soll. Daher beschränkten die Ingenieure ihre Lösung darauf, nur den Traffic zu erkennen und zu blockieren, der auch im Normalbetrieb gesperrt worden wäre. Erlaubter Traffic war davon nicht betroffen.
Um die Suche zu unterstützen, entschieden sie sich für die Nutzung von SWG-Telemetrie, die in der Regel die URL, die zugehörige Kategorie und die entsprechende Aktion enthält.

Eine vorhandene Datenverarbeitungspipeline wurde genutzt, um einen Index der 100’000 weltweit am häufigsten blockierten Domains zu erstellen. Am Ende der ersten Woche wurde die erste Version des Index auf allen Kundenseiten zusammen mit dem temporären URL-Filter-Feed bereitgestellt. Sie war einsatzbereit, falls die Endpunkte des Anbieters offline gingen.
Laufende Kommunikation
Während Raphi die Fortschritte der technischen Betriebsteams überwachte, koordinierte er weiterhin Kommunikationsupdates über alle Kanäle. Er stellte fest, dass die Unterrichtung der Führungsteams zwei Vorteile hatte: Erstens hielten sich die Führungskräfte eher zurück, wenn sie wussten und verstanden, was getan wurde. Zweitens brachten sie durch gezielte Fragen ihre Erfahrung ein und verbesserten so die Reaktionsfähigkeit.
Abbildung 8: Laufende Kommunikation.
Eine interne FAQ wurde eingerichtet, damit Mitarbeitende mit Kundenkontakt über präzise Informationen verfügten, um verschiedene Kundenanliegen zu klären. So konnten sich die Ingenieure, die an Lösungen arbeiteten, stärker auf ihre eigentlichen Aufgaben konzentrieren. Zudem wurde der High-Level-Plan intern kommuniziert und allen Mitarbeitenden zugänglich gemacht.
Für die externe Kommunikation nutzte Open Systems weiterhin sein Webportal, um Informationen an den gesamten Kundenstamm zu verteilen. E-Mail wurde zu diesem Zeitpunkt nur sparsam und in bestimmten Fällen verwendet.
Alle sechs Stunden fand ein Sitrep-Meeting mit wichtigen Mitarbeitern statt. Mit zunehmender Stabilisierung der Situation wurden diese Meetings jedoch seltener.
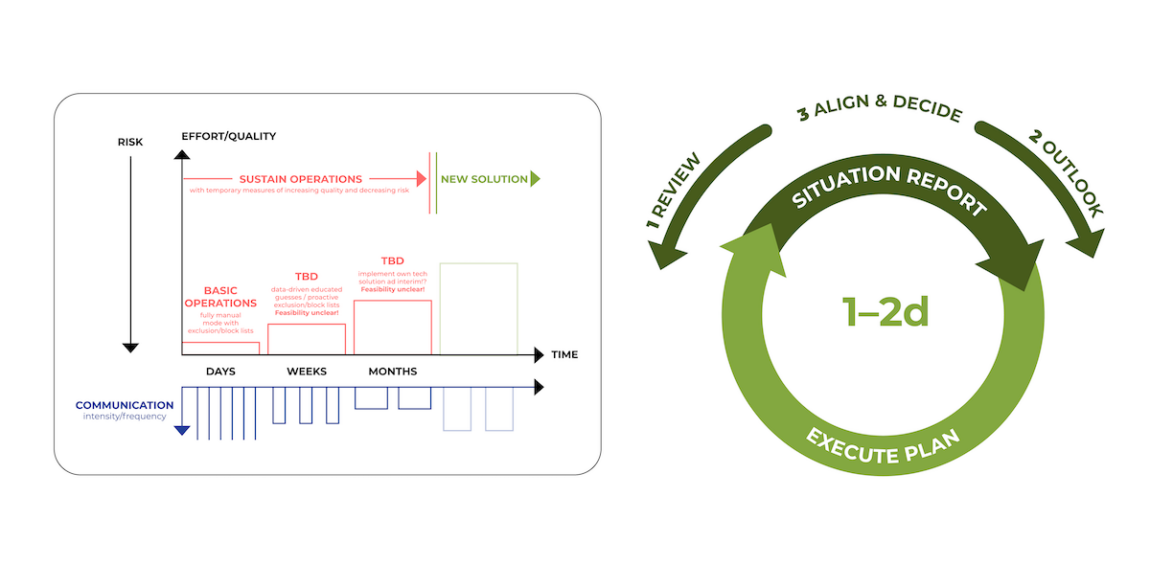
Abbildung 9: Kreislauf aus: 1. Review, 2. Outlook 3. Align & Decide.
Bei jedem dieser Meetings prüfte Chris als Sustaining Operations Lead zunächst, was getan und geplant war. Danach folgte der New Solution Lead, gefolgt von Raphi als Communication Lead. Durch diesen Prozess wurden nicht abgestimmte Entscheidungen sofort sichtbar, konnten diskutiert und gegebenenfalls angepasst werden.
Die Situation verlief reibungslos, bis eine Flut von Tickets bei Mission Control einging. Die Endpunkte des Anbieters wurden offline geschaltet. Glücklicherweise erholten sie sich nach 15 Minuten, sodass Notfallpläne nicht aktiviert werden mussten. Dennoch erinnerte dies daran, dass die Lage weiterhin instabil war und die technischen Bemühungen mit Hochdruck fortgesetzt werden mussten.
Am Ende der ersten Woche berichtete Raphi:
- Erste Risikominderung wurde aktiviert ✅
- Neue Lösung wurde erforscht ✅
- Regelmässige Meetings und Kommunikation ✅
Erste Monate
Aus Wochen wurden Monate, und es stellte sich allmählich Routine ein – ein gutes Zeichen.
Nun reichten wöchentliche Sitrep-Meetings aus. Das lokale Feed zur Aufrechterhaltung des Betriebs war stabil, und der Fokus verlagerte sich auf die Entwicklung der neuen Lösung.
Erstellung einer neuen URL-Filter-Lösung
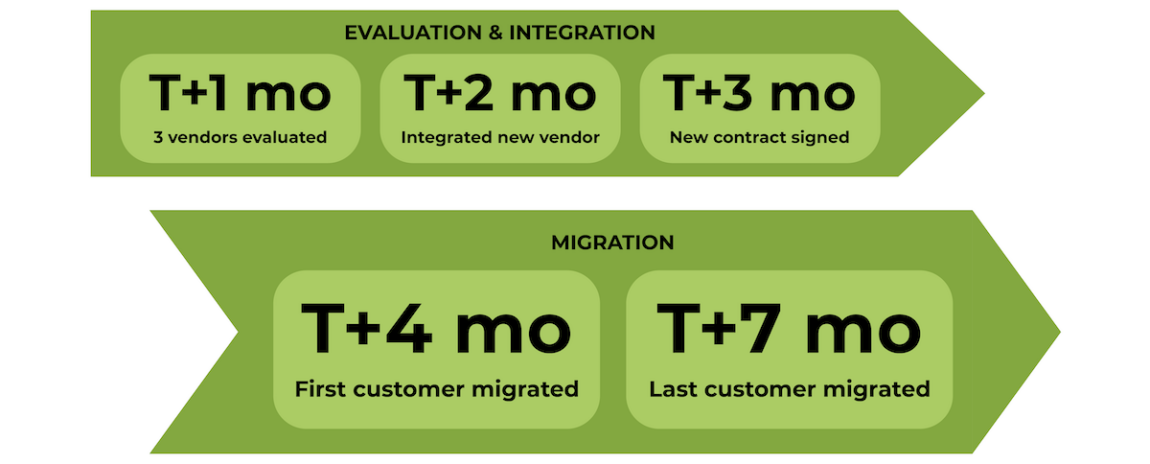
Abbildung 10: Zeitrahmen für die Erstellung einer neuen URL-Filter-Lösung.
Der Austausch eines URL-Filters ist ein langwieriger und komplexer Prozess.
- Im ersten Monat wurden drei Anbieter evaluiert.
- Die Integration des bevorzugten Produkts begann sofort, nachdem es erfolgreich auf produktiven Secure Weg Gateways von Open Systems getestet wurde.
- Drei Monate nach Beginn der Krise wurde der Vertrag mit einem neuen Anbieter unterzeichnet.
- Einen Monat später startete die erste Kundenmigration.
- In dieser frühen Phase der Migration traten technische Herausforderungen in Mission Control auf. Die Secure Web Gateways von Open Systems sind in rund 180 Ländern im Einsatz, was selbst in Regionen mit heterogenen Konnektivitätsumgebungen eine reibungslose Funktionalität verlangt.
- Die Technical Account Manager migrierten die Kunden schrittweise nacheinander. Dieser bewusst konservativere Ansatz stand im Gegensatz zu einer sofortigen Migration aller Kunden. Ziel war es, die zuverlässige Funktionalität der Systeme zu gewährleisten, da diese über Jahre hinweg an die spezifischen Unternehmensrichtlinien der Kunden angepasst worden waren.
- Sieben Monate nach Beginn der Krise wurde der letzte Kunde migriert.
Die Katastrophe war abgewendet.
Fun Fact: Die alten Anbieter-Endpunkte in der Cloud waren weiterhin erreichbar und boten noch Service an.
Abschluss und Rückblick
Open Systems erreichte ein entscheidendes Ziel: Die Sicherheit und Compliance seiner Kunden zu gewährleisten und gleichzeitig die Geschäftskontinuität sicherzustellen. Zum Abschluss der Krisenbewältigung wollten Raphi und Chris die Erfolge und Misserfolge sowie deren Ursachen im Kontext der Ereignisse analysieren.
Technische Perspektive
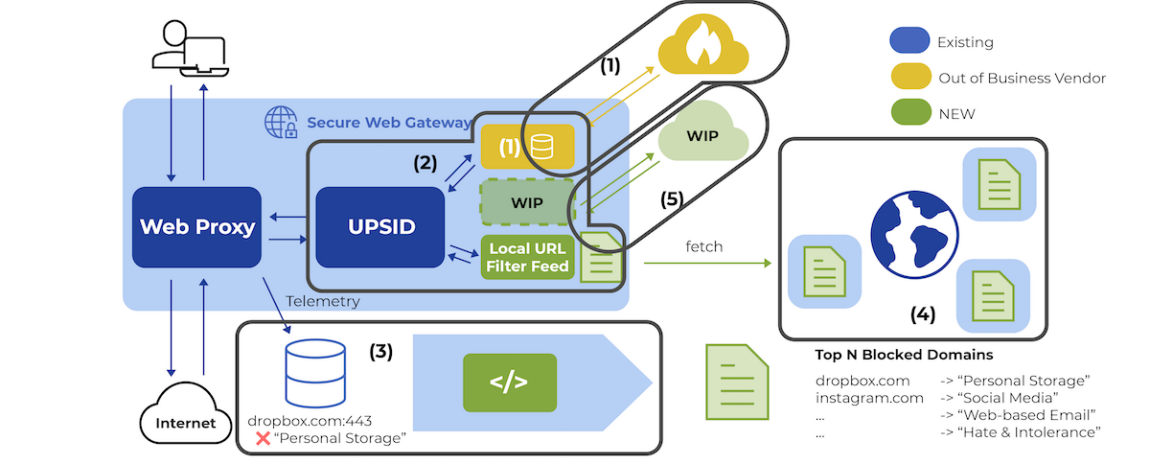
Abbildung 11: Technische Perspektive.
Aus technischer Sicht fiel Chris Folgendes auf:
- Ein proprietärer Daemon im Hot Path des Web-Traffics der Kunden – mit einem fragwürdigen Lizenzvalidierungsmechanismus, der zum Ausfall führen konnte, sobald die Endpunkte des Anbieters nicht erreichbar waren. Das klingt nach Ärger. Hätten die Ingenieure von Grund auf neu begonnen, hätten sie dieses System sicher anders konzipiert. Doch die Evaluierung und Auswahl eines URL-Filter-Anbieters ist nicht vergleichbar mit der Wahl einer Public Cloud, eines Frontend-Frameworks oder einer Programmiersprache. Die Optionen sind begrenzt.
- In dieser Krise mussten alle ihre Komfortzone verlassen. Für die Engineering-Teams war es ein grosser Vorteil, sich auf vertraute Tools, Technologien und Prozesse stützen zu können. So bot ihnen der Unified Policy and Security Intelligence Daemon die nötige Abstraktion zwischen dem zentralen Web Proxy und den verschiedenen Intelligence-Feeds. Das erleichterte nicht nur die Integration und Schadensbegrenzung, sondern später auch den Austausch einzelner Komponenten erheblich.
- Erfahrene Ingenieure mit Betriebskenntnissen waren entscheidend für effektive, datengesteuerte Entscheidungen – ebenso wie die Telemetrie und eine bestehende Datenverarbeitungspipeline.
- Die Konfigurations- und Laufzeitplattform von Open Systems spielte Hotfixes in der Regel innerhalb von 24 Stunden auf alle Secure-Web-Gateway-Bereitstellungen aus – selbst in Regionen mit schlechter Konnektivität und bei unterschiedlichsten Kunden-Set-ups in verschiedenen Branchen.
- Für die Ablösung des bisherigen Lieferanten stand bereits eine Shortlist mit drei alternativen Anbietern bereit – proaktiv gescoutet zwei Jahre zuvor im Zuge von Vertragsverhandlungen. Der Produktmanager konnte diese Liste sofort nutzen.
Krisengeführte Perspektive
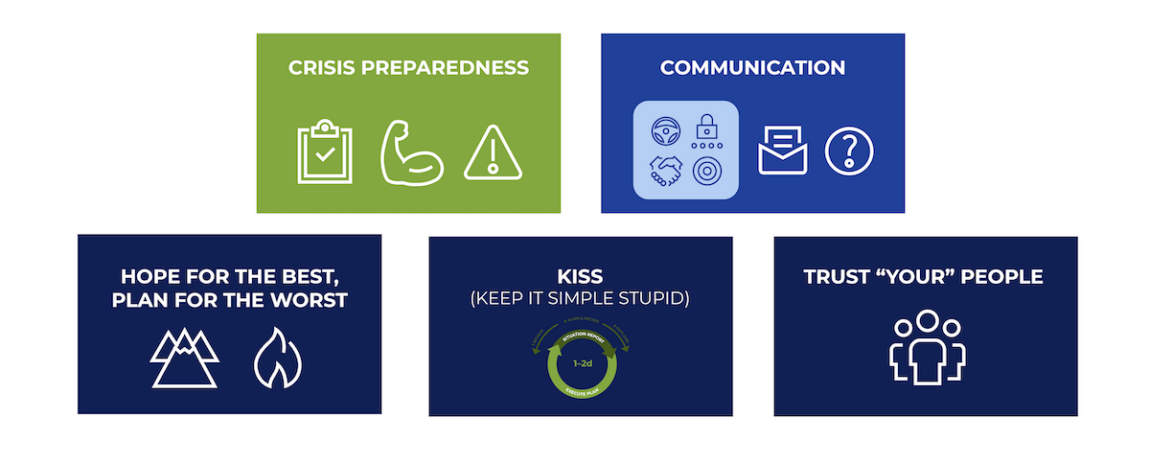
Abbildung 12: Krisengeführte Perspektive.
Aus Sicht der Krisenführung beobachtete Raphi Folgendes:
- Obwohl Prozesse vorhanden waren, hätten regelmässige, proaktive Krisenschulungen und inszenierte Krisenszenarien den Engineering-Teams im Vorfeld geholfen. Diese Art der Schulung ist inzwischen ein fester Bestandteil im Unternehmen.
- Die Grundregeln für schnelle und transparente Kommunikation waren gut. In der Praxis erwiesen sich jedoch kontinuierliche Massenmailings als ineffizient und wenig wirksam. Deutlich besser funktionierte der News-Bereich im Kundenportal. Entscheidend war, realistische Kundenerwartungen über mehrere Monate hinweg zu managen.
- “Hope for the best but plan for the worst” erwies sich als hilfreiches Prinzip. Obwohl die Endpunkte des Anbieters meist erreichbar waren, konnten sich die Ingenieure nicht darauf verlassen. Sie konzentrierten sich auf das, was sie kontrollieren und abschwächen konnten, während sie parallel den URL-Filter ersetzten.
- Der Krisenreaktionsprozess funktionierte gut: ein klarer Plan mit definierten Verantwortlichkeiten, gefolgt von gezielten Massnahmen. Keep it simple hat sich besonders bewährt: Neue Teammitglieder konnten sich schnell einarbeiten, und das gesamte Unternehmen – vom Führungsteam bis zu den Ingenieuren – verstand die Strategie.
- Auch das Prinzip “Trust your people” zahlte sich aus. Es bedeutet, die eigenen Mitarbeiter wirklich zu kennen – ihre Stärken, ihr Wissen und ihre Fähigkeiten. Wenn eine Krise eintritt, ist es dann viel einfacher, sich zusammenzuschliessen und gemeinsam effektiv zu handeln.
Fazit
Vermeiden Sie Krisen, bevor sie entstehen.
Aber wenn es zu einer Krise kommt:
- Treten Sie geschlossen auf und arbeiten Sie zusammen.
- Machen Sie einen klaren, einfachen Plan.
- Übernehmen Sie Verantwortung.
Dieser Blogbeitrag basiert auf einer Präsentation, die auf der SREcon im Oktober 2024 gehalten wurde.
ÄHNLICHE BLOGBEITRÄGE

Blog
Wenn ein funktionierendes Testsystem zum Engpass wird und wie wir das Problem gelöst haben

Blog
Warum Human-in-the-Loop an Grenzen stösst: Weshalb maschinelle Vorschläge allein nicht genügen

Blog
95 % aller KI-Pilotprojekte scheitern. Was wir bei der Einführung von KI in einem regulierten Unternehmen gelernt haben
Lassen Sie die Komplexität
hinter sich
Sie möchten auch von der Open Systems SASE Experience profitieren? Unsere Experten helfen Ihnen gern weiter.
Kontakt