
Von Minuten zu Sekunden: Die Ingenieurskunst hinter intelligenteren Alerts

Alerting gehört zu den unterschätzten Bereichen der IT, in denen echte Exzellenz meist unsichtbar bleibt. Wenn alles reibungslos funktioniert, fällt kaum jemandem auf, wie viel es tatsächlich braucht, um alles richtig zu machen. Werden Alerts korrekt ausgelöst, schaffen sie Vertrauen – leise und subtil. Feuern sie jedoch falsch, erzeugen sie Lärm, Verwirrung und letztlich „Alert Fatigue“. Bei Open Systems, wo rund 10’000 weltweit verteilte Deployments in eine einheitliche Observability-Plattform einfliessen, ist zuverlässiges Alerting nicht nur eine technische Anforderung, sondern ein Versprechen an unsere Kunden.
Dieses Versprechen wird durch etwas gestützt, das nur wenige (wenn überhaupt) SASE-Anbieter für sich beanspruchen können: eine einheitliche Plattform, die jeden Service, jedes Signal und jeden Alert integriert. Sie basiert auf tiefgreifender Service-Expertise und durchgängiger End-to-End-Engineering-Kompetenz.
Dies ist die Geschichte darüber, wie die Ingenieure meines Teams eine feinsinnige Designherausforderung im Prometheus AlertManager entdeckt, das Problem neu eingeordnet und anschliessend pragmatische, wirkungsvolle Verbesserungen umgesetzt haben.
Was AlertManager leistet – und warum das in einer einheitlichen Plattform entscheidend ist
In unserer Observability-Pipeline fungiert AlertManager als einer der zentralen Entscheidungspunkte, an denen eingehende Signale zusammenlaufen. Metriken strämen kontinuierlich aus unseren Services ein, eingehende Log-Meldungen werden in numerische Indikatoren umgewandelt, und von den Service-Teams erstellte Regeln legen fest, was als relevantes Signal gilt.
Zeigt ein Deployment beispielsweise über längere Zeit eine hohe CPU-Auslastung, weiss das verantwortliche Service-Team genau, was „hoch“ im jeweiligen Kontext bedeutet. Dieses Wissen wird direkt in Alert-Regeln abgebildet. AlertManager bewertet diese Regeln in Echtzeit und entscheidet, ob ein Ereignis lediglich protokolliert, ein Engineering-Team über eine Messaging-App informiert oder in schwerwiegenderen Fällen ein kundenrelevantes Ticket erstellt wird. Letzteres wird von unserem Expertensupport Mission Control rund um die Uhr bearbeitet.
Da diese Alert-Regeln von Fachleuten stammen, die ihre Services über Jahre hinweg entwickelt und betrieben haben, spiegelt jeder Alert eine bewusste fachliche Absicht wider. Und weil alles in einer einheitlichen Plattform zusammengeführt wird, lassen sich Alerts über Tausende von Deployments hinweg aggregieren, deduplizieren und in Kontext setzen. So entsteht aus digitalem Rauschen tatsächlich handlungsrelevante Information.
Dieser Ansatz ist in der SASE-Branche alles andere als selbstverständlich. Häufig bleibt Monitoring auf Infrastruktur-Ebene, ist generisch oder wird nachträglich angebaut. Bei Open Systems hingegen entstehen Monitoring und Alerting an der Quelle – entwickelt von den Menschen, die ihre Services am besten kennen. Für mich ist das ein zentraler Differenzierungsfaktor, der mit wachsender Skalierung zunehmend an Bedeutung gewinnt.
Wenn Designannahmen auf operative Realität treffen
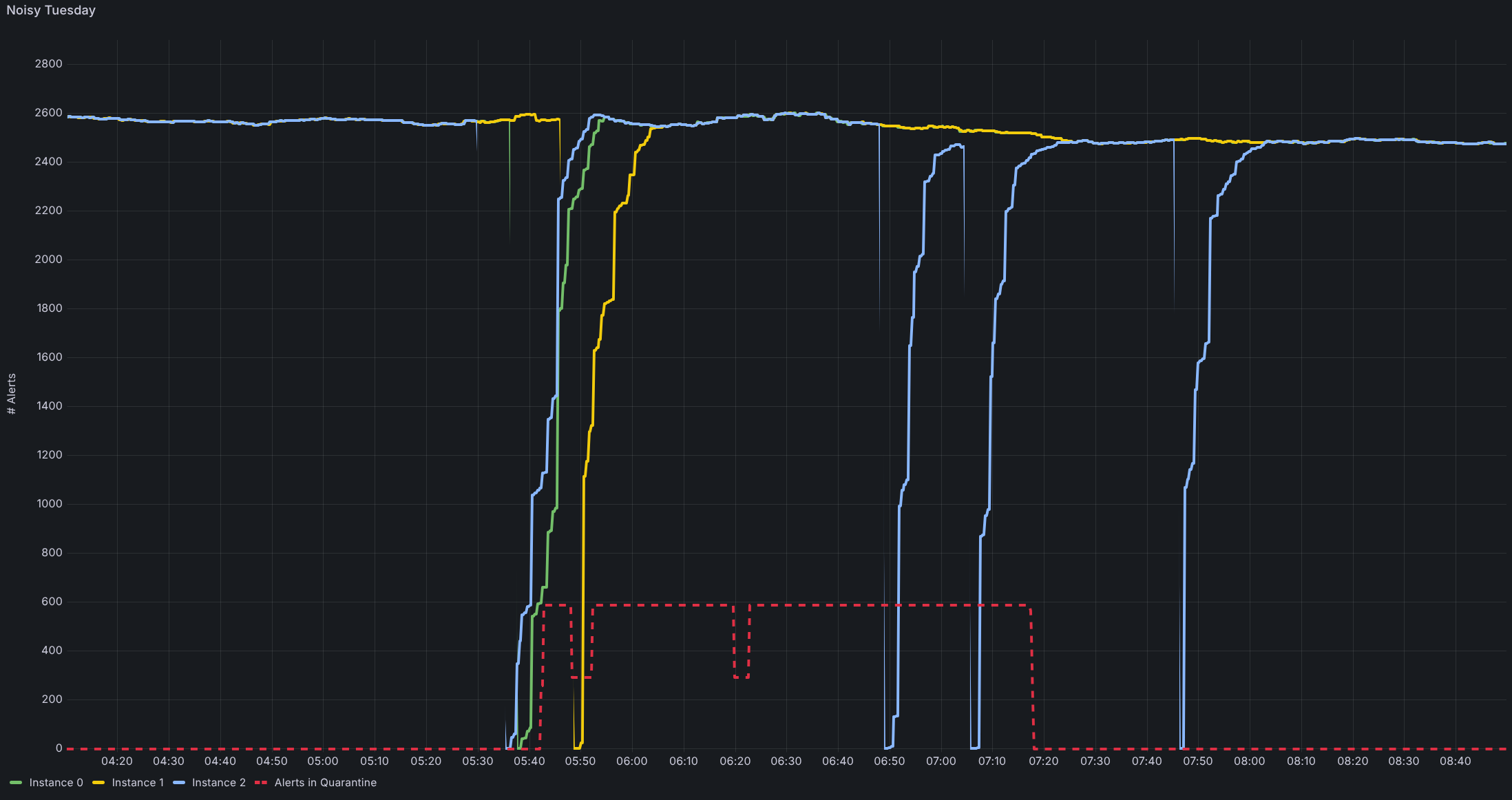
Über lange Zeit hinweg arbeitete AlertManager zuverlässig. Irgendwann zeigte sich jedoch ein wiederkehrendes Muster – fast immer dienstags. Während routinemässiger Neustarts unserer Monitoring- und Alerting-Infrastruktur wurde Mission Control plötzlich mit Ticket-Events überschwemmt: manchmal Hunderte, manchmal Tausende. Ein Teil davon war für Kunden sichtbar, ein anderer nicht.
Aus Kundensicht glich dies einer Flut von Incidents. Intern hingegen waren die Systeme stabil und gesund. Schnell wurde klar, dass wir genauer hinschauen mussten. Die Ursache erwies sich als subtil: Bei jedem Neustart verlor AlertManager vorübergehend seinen internen Zustand, der festhält, welche Alerts aktuell aktiv sind. Diese „Amnesie“ ist kein Fehler, sondern Teil seiner ursprünglichen Designphilosophie.
AlertManager geht implizit davon aus, dass die Systemlast überschaubar ist, Alert-Signale kontinuierlich eintreffen und sich der Zustand nach einem Neustart innerhalb weniger Sekunden wieder aufbaut. In klassischen, kleineren Umgebungen ist diese Annahme durchaus valide.
Open Systems jedoch sprengt diesen Rahmen gleich mehrfach:
- Unser Signalvolumen ist enorm – deutlich höher als in den meisten AlertManager-Installationen.
- Unsere Alerts lösen kundenrelevante Events aus; Fehlalarme sind daher nicht tolerierbar.
- Unsere Plattform ist stark vernetzt, sodass viele Komponenten zur Wiederherstellung des Gesamtzustands beitragen.
In Kombination führten diese Faktoren zu einem Kipppunkt. Die Rekonstruktion des „Status quo“ dauerte nach einem Neustart nicht mehr Sekunden, sondern Minuten. In dieser Zeit tat AlertManager das einzig Vorsichtige, was ihm möglich war: Er löste Benachrichtigungen erneut aus.

Ein Ingenieur brachte es treffend auf den Punkt: „Es hat nicht versagt. Es hat genau das getan, wofür es entworfen wurde – nur nicht das, was wir in unserem Kontext brauchten.“
Diese Erkenntnis markierte den entscheidenden Wendepunkt.
Denkweisen ändern: vom Tuning zum Verstehen
Als erste Sofortmassnahme führte das Team eine zusätzliche Komponente in der Alerting-Pipeline ein: die Alert Quarantine. Diese einfache Heuristik erkennt Ereignisfluten, die nicht auf ein reales Problem zurückzuführen sind, und verhindert, dass sie automatisch in kundenrelevante Tickets münden. Damit liess sich die Situation für Kunden unmittelbar entschärfen, während parallel Zeit für eine fundierte Ursachenanalyse gewonnen wurde.
Der nächste Schritt war naheliegend: klassisches Tuning. Intervalle wurden angepasst, Timer verändert, Gossip-Parameter feinjustiert. Doch trotz aller Bemühungen blieb der Effekt begrenzt – die „lauten Dienstage“ verschwanden nicht.
Erst als das Team seinen Ansatz grundlegend änderte, kam Bewegung in die Sache. Statt AlertManager zu einem Verhalten zu drängen, das seiner Konzeption widersprach, hinterfragten sie seine grundlegenden Annahmen. Dabei wurde klar: Es lag keine Fehlkonfiguration vor, sondern eine strukturelle Diskrepanz zwischen Designintention und betrieblicher Realität.
Der entscheidende Aha-Moment wurde durch einen Kommentar in einem Upstream-GitHub-Issue ausgelöst: „AlertManager garantiert keine genau-einmaligen Benachrichtigungen.“
Für Dashboards oder kleine Setups ist das unkritisch. Doch wenn Alerts Mission-Control-Tickets auslösen – und in manchen Fällen sogar SMS an einen IT-Leiter senden – ist „genau einmal“ plötzlich von zentraler Bedeutung.
Damit hörte das Team auf, einen nicht existierenden Bug zu beheben, und begann, eine Lösung zu entwickeln, die den realen Rahmenbedingungen gerecht wird.
Eine pragmatische, elegante Lösung – der Snapshot-Ansatz
Der Durchbruch entstand während eines internen Hackathons. Eine KI-gestützte Coding-Session brachte zunächst ein vollständiges Datenbank-Backend hervor, das den gesamten Alert-Zustand persistent speicherte. Die Lösung war kreativ und funktional – für den produktiven Einsatz jedoch zu komplex.
Eine zusätzliche Datenbank hätte operative Komplexität erhöht und neue Fehlerquellen geschaffen. Zudem widersprach sie einem unserer Leitprinzipien: so viel wie nötig, so wenig wie möglich.
Stattdessen reduzierte das Team die Idee auf ihr Wesentliches:
- Beim Herunterfahren schreibt AlertManager einen vollständigen Snapshot seines aktuellen Alert-Zustands auf ein leichtgewichtiges, persistentes Volume.
- Beim Neustart wird dieser Snapshot sofort geladen und der Zustand nahezu augenblicklich wiederhergestellt.
Dieser Snapshot-basierte Ansatz verlieh AlertManager genau das, was ihm fehlte: ein Gedächtnis – ohne seine grundlegende Designphilosophie zu verändern. Kein Redesign, keine zusätzliche Infrastruktur, sondern gezielte Persistenz zum richtigen Zeitpunkt.
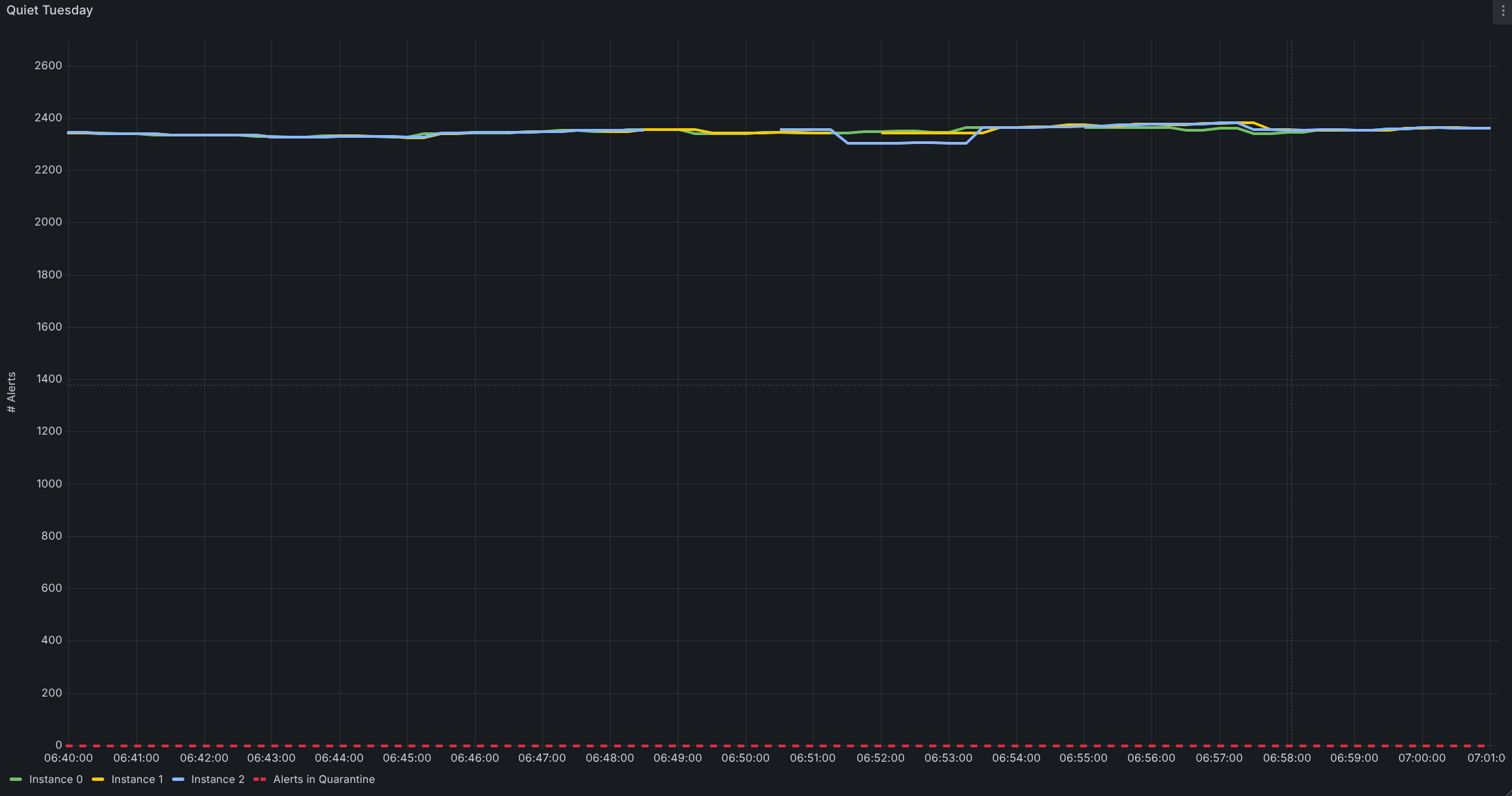
Das Ergebnis war deutlich messbar: Die Startzeit sank von mehreren Minuten auf unter 30 Sekunden – jene Schwelle, unterhalb derer kein erneutes Auslösen mehr stattfindet. Die Dienstag-Fluten verschwanden schlagartig.
Das Resultat: sauberere Alerts, neues Vertrauen und eine stärkere Plattform
Die Wirkung war unmittelbar. Mission Control erlebt seither keine Schübe doppelter Ticket-Events mehr bei Neustarts von AlertManager. Engineering-Teams verlieren keine Zeit mehr mit vermeidbaren Eskalationen oder unnötigen Post-Mortems. Und Kunden, die Alert-Benachrichtigungen abonniert haben, erhalten weniger Fehlalarme sowie klarere und besser verwertbare Signale – an jedem Wochentag, auch dienstags.
Ebenso wichtig ist der interne Effekt: Die Ingenieure haben ihr Vertrauen in die Alerting-Pipeline zurückgewonnen. Das System verhält sich nun konsistent, vorhersehbar und respektvoll – genau so, wie man es von einer Plattform erwartet, die Tausende verteilter Deployments überwacht.
Auch ausserhalb von Open Systems stiess diese Arbeit auf Resonanz. Nach einer Konferenzpräsentation berichteten mehrere Teilnehmende, dass sie mit ähnlichen Problemen konfrontiert seien, jedoch bislang davon ausgegangen seien, allein damit zu stehen. Unsere Lösung bestätigte ihre Erfahrungen und löste weiterführende Diskussionen in der Observability-Community aus.
Das grössere Bild – warum Open Systems dort überzeugt, wo andere an Grenzen stossen
Diese Engineering-Geschichte verdeutlicht etwas Grundlegendes an unserer Plattform. Es ist kein Zufall, dass wir an die Designgrenzen von AlertManager gestossen sind. Viele Anbieter werden das nie – schlicht, weil sie weder dieses Signalvolumen noch diese Service-Vielfalt oder diese Form der kundenintegrierten Automatisierung betreiben.
Der Ansatz von Open Systems ist einzigartig, weil:
- jedes Service-Team seine Alert-Logik auf Basis tiefgehender Domänenkenntnis selbst definiert,
- unsere einheitliche Plattform all diese Signale in einem kohärenten Observability-System zusammenführt,
- Alerts echte fachliche Bedeutung tragen statt generische Schwellenwerte abzubilden und Kunden gezielt zum Handeln auffordern,
- das System auf über 10’000 Deployments weltweit skaliert und SASE-Services für unterschiedlichste Branchen bereitstellt.
Gerade diese durchgängige Integration – vom Service-Design über die Plattformlogik bis zur Kundenbenachrichtigung – ermöglicht eine Observability-Erfahrung, die präzise, verlässlich und im grossen Massstab handlungsfähig ist.
Die Snapshot-Lösung ist dabei nur ein Beispiel dafür, wie tief unsere Ingenieure ihre Systeme verstehen und wie konsequent sie daran arbeiten, das Vertrauen unserer Kunden zu schützen.
Präzises Alerting – und darüber hinaus
Wirksames Alert-Management erfordert Präzision, Bescheidenheit und eine Engineering-Kultur, die über Symptome hinausblickt, um Ursachen zu verstehen.
Die Arbeit meines Teams am AlertManager steht exemplarisch dafür. Sie zeigt die handwerkliche Sorgfalt und den Pragmatismus, die unsere Plattform prägen – und die Open Systems in einer Branche differenzieren, in der Monitoring allzu oft nur eine Nebenrolle spielt.
Gutes Alerting entsteht nicht zufällig. Es entsteht, weil Menschen sich bewusst darum kümmern, es genau so zu gestalten.



Lassen Sie die Komplexität
hinter sich
Sie möchten auch von der Open Systems SASE Experience profitieren? Unsere Experten helfen Ihnen gern weiter.
Kontakt