
Klarheit trotz Datenflut


Im Tech-Blogbeitrag Telemetry to Tickets hat unser Kollege thematisiert, wie Open Systems Telemetriedaten mithilfe von Observability in umsetzbare Erkenntnisse verwandelt. Gemeint ist das Sammeln von Signalen über verschiedene Services hinweg, deren Standardisierung und die Aufbereitung in einer Form, mit der Menschen effektiv arbeiten können.
Unser Team ist auf Logs und Metriken spezialisiert – und genau dort wird das Observability-Framework greifbar. Logs und Metriken bilden die Ausführungsebene und sind damit fester Bestandteil des täglichen Betriebs. Kunden benötigen sie fürs Debugging, Service-Teams für Analysen und Innovationen, und Open Systems Mission Control setzt sie gezielt zur schnellen und fundierten Störungsbehebung ein.
Vom Heuhaufen zu Klarheit
Jedes System erzeugt Daten. Allein die von Open Systems verwalteten Firewalls können an einem einzigen Tag mehr als 13 Terabyte an Logs produzieren. Ergänzt man dies um Metriken wie CPU-Temperaturen, Bandbreitendurchsatz oder Authentifizierungszahlen, entsteht eine wahre Datenflut.
Früher bedeutete Debugging, Logfiles direkt auf einer Maschine zu öffnen und manuell nach der einen Zeile zu suchen, die erklärte, warum ein Benutzer keinen Zugriff auf einen Service hatte. Das war frustrierend – für Kunden wie auch für Mission Control –, zeitaufwendig und in kritischen Situationen schlicht zu langsam.

Wir wollten das ändern. Unser Ziel war einfach: die überwältigende Datenmenge in die Hand nehmen und für alle nutzbar machen.
Standardisierte Observability in der Praxis
Unser Ansatz baut auf dem Observability-Framework auf, mit besonderem Fokus auf Konsistenz und Benutzerfreundlichkeit.
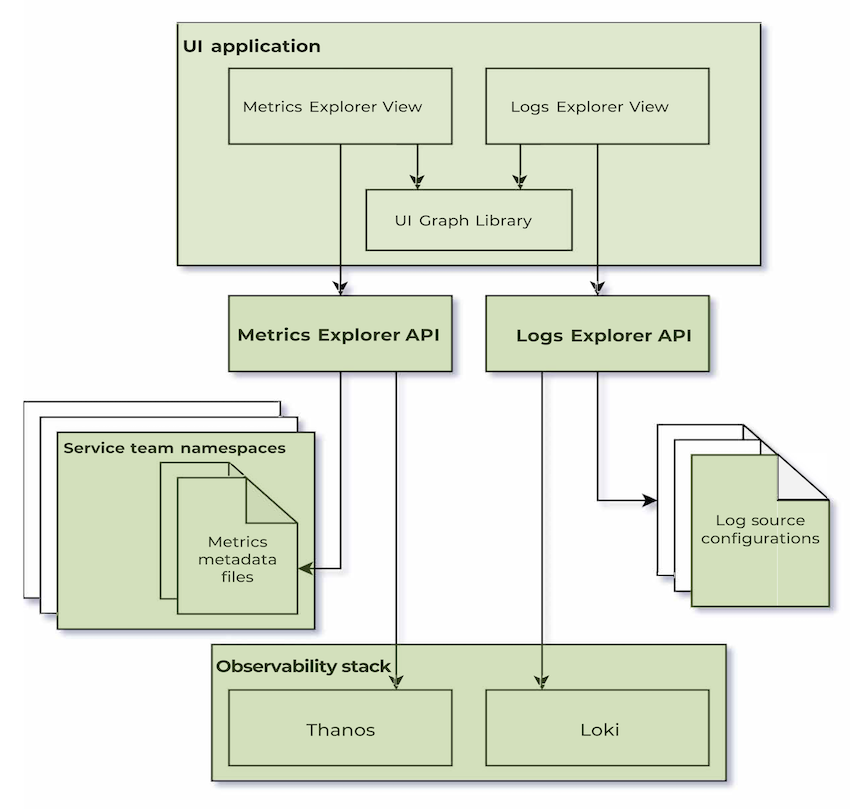
- Metadaten-Files erfassen automatisch Business-Logik aus einer Vielzahl von Konfigurationsdateien und führen sie in einer zentralen Quelle der Wahrheit zusammen. So lassen sich beispielsweise einzelne CPU-Temperaturmessungen zu einem KPI bündeln, der den Service-Zustand aussagekräftig widerspiegelt. Metadaten dienen zudem als Grundlage für Diagrammwahl, Einheitenstandardisierung und weitere Optimierungen.
- Log-Source-Konfigurationen definieren, wie spezifische Logzeilen im Observability-Stack gefunden werden und welche Berechtigungen für deren Einsicht gelten. In bestimmten Fällen reduzieren sie sehr umfangreiche Metadaten auf die wirklich relevanten Felder.
- Unified Logs- und Metrics-API sowie eine dedizierte Frontend-Library stellen APIs bereit, mit denen sich diese datenreichen Metriken in weniger als fünf Minuten abrufen, verarbeiten und visualisieren lassen.
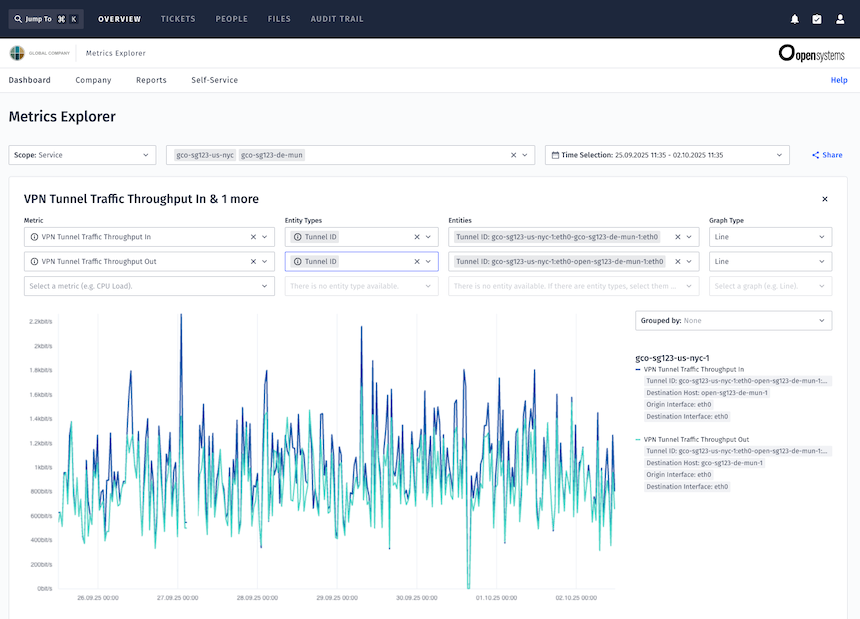
- Metrics Explorer liefert sofort nutzbare Diagramme für Trendanalysen, Kapazitätsplanung und Anomalieerkennung.
- Logs Explorer ermöglicht einen nahtlosen Wechsel zwischen historischer Log-Analyse und Live-Streaming und unterstützt damit sowohl langfristige Untersuchungen als auch Echtzeit-Debugging.
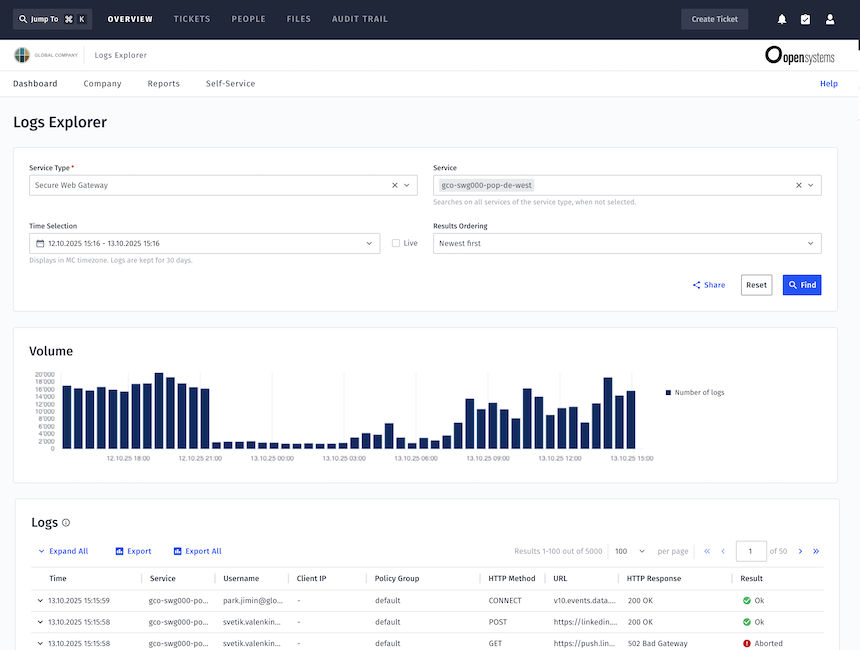
Der Effekt dieses Designs ist deutlich messbar. Als das Team Firewall-Logs in den Logs Explorer integrierte, war die Arbeit an einem einzigen Tag abgeschlossen – ein Aufwand, der zuvor mehrere Wochen Engineering-Zeit beansprucht hatte.
Skalierung und Sicherheit
Der Umgang mit Daten in dieser Grössenordnung erforderte durchdachte technische Lösungen. Dazu gehören:
- Chunkading – Aufteilung von Abfragen in Zwei-Stunden-Intervalle, um Timeouts zu vermeiden.
- Asynchrone Abfragen – Teilresultate werden angezeigt, selbst wenn einzelne Chunks fehlschlagen.
- Optimierte Filterung – einfache Abfragen (z. B. „alle Logs eines Services“) liefern sofort Ergebnisse, während komplexe Suchanfragen weiterhin unterstützt werden.
Genauso zentral ist das Thema Sicherheit. Logs können sensible Informationen enthalten, weshalb eine strikte Autorisierung sicherstellt, dass Benutzer ausschliesslich auf die Daten zugreifen, für die sie berechtigt sind. Zusätzlich wurde das System durch externe Penetrationstests gehärtet – ein klares Zeichen für seine Rolle als zentrale Sicherheitsinfrastruktur.
Mehrwert für Kunden
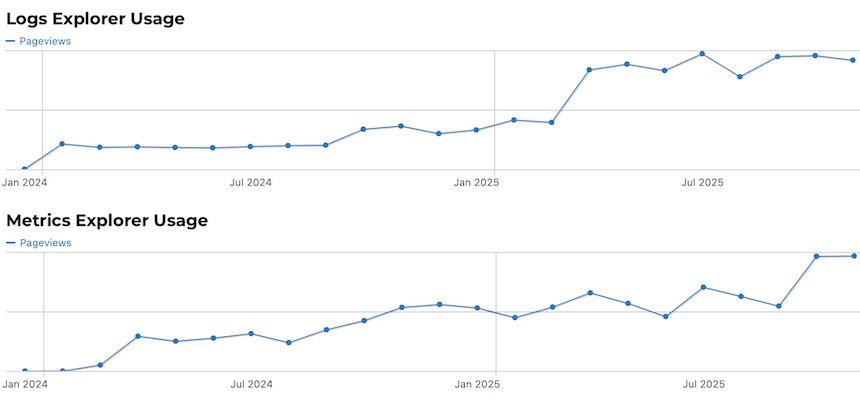
Für Kunden waren diese Änderungen spürbar transformativ. Logs und Metriken zählen inzwischen zu den meistgenutzten Werkzeugen im Open-Systems-Kundenportal:
- Logs Explorer ist heute das meistgenutzte Debugging-Tool – häufiger als jede andere Portal-Funktion.
- Metrics Explorer hat seine Nutzung im vergangenen Jahr verdoppelt, mit weiterhin stetigem Wachstum.
Das Kundenfeedback bestätigt diesen Trend eindrücklich. Ein Kunde formulierte es so:
„Den alten Firewall-Log-Viewer im Portal habe ich als Tool nie geschätzt. Ihr könnt euch daher nicht vorstellen, wie glücklich ich war, als ich nach Firewall-Logs suchte und den neuen Logs Explorer fand. Das ist definitiv eine Verbesserung – ich finde jetzt viel schneller, was ich brauche.”
Auch andere heben die neuen Möglichkeiten als zentrale Erleichterung im Arbeitsalltag hervor. So ermöglicht das gleichzeitige Filtern von Secure-Web-Gateway-Logs über mehrere Services hinweg, Muster schneller zu erkennen und Probleme über einen breiteren Datenbestand hinweg zu analysieren. Ebenso wurden der neu gestaltete Firewall Logs Explorer und seine intuitivere Benutzeroberfläche als klare Verbesserungen wahrgenommen.
Über einzelne Funktionen hinaus zeigt sich der eigentliche Wandel jedoch in der Art und Weise, wie Kunden heute arbeiten. Sie können den Weg eines Benutzers über Firewall-, Proxy- und Authentifizierungsereignisse hinweg nachvollziehen und genau erkennen, wo ein Zugriff scheitert. Logs lassen sich live streamen, während neue Firewall-Regeln getestet werden, und ihr Verhalten kann in Echtzeit beobachtet werden. Die Explorer dienen sogar dazu, externe Provider zu überprüfen – etwa um zu verifizieren, ob ein ISP die zugesagte Leistung erbringt. Neue Metriken oder Log-Quellen, die von Service-Teams hinzugefügt werden, stehen Kunden sofort zur Verfügung, ohne auf Releases zu warten oder zusätzliche Kosten zu verursachen.
Für viele fühlt sich das an, als würde der Vorhang über ihrer Infrastruktur geöffnet. Was früher hinter Support-Tickets und Annahmen verborgen war, ist heute transparent, schnell zugänglich und jederzeit verfügbar.
Vorteile für Mission Control und Engineering Teams
Auch intern ist der Wandel deutlich spürbar. Mission-Control-Engineers müssen nicht mehr tief in rohe Host-Logs eintauchen, um Incidents zu analysieren. Stattdessen arbeiten sie mit denselben Werkzeugen wie die Kunden, was eine schnellere Ticket-Bearbeitung und eine engere Zusammenarbeit ermöglicht.
Für Engineering- und Service-Teams ergeben sich strukturelle Vorteile. Da alles auf konsistenten APIs und Schemas basiert, ist die Integration neuer Services in das Observability-Framework kaum mehr als eine Konfigurationsaufgabe. Das reduziert den Engineering-Aufwand erheblich und schafft Freiräume für Innovationen – etwa für neue Features, intelligentere Dashboards oder KI-gestützte Analysen.
Am wichtigsten ist jedoch die gemeinsame Single Source of Truth. Kunden, Mission Control und Engineering-Teams arbeiten mit denselben Daten, denselben Interfaces und derselben Sprache. Diese gemeinsame Basis reduziert Reibungsverluste, stärkt das Vertrauen und beschleunigt fundierte Entscheidungen.
Warum Logs und Metriken entscheidend sind
Logs und Metriken mögen auf den ersten Blick technisch und detailreich wirken, doch ihr Nutzen ist unmittelbar und breit gefächert:
- Weniger Ausfallzeiten durch schnellere Problemlösung
- Mehr Kundenautonomie dank leistungsfähigem Self-Service
- Konsistenz und Vertrauen durch eine zentrale Quelle der Wahrheit
- Skalierbarkeit und Flexibilität, um neue Datenquellen schnell einzubinden
Während Mitbewerber oft fragmentierte Lösungen anbieten und Teams zwingen, mit unterschiedlichen Tools und Abfragesprachen zu arbeiten, setzt Open Systems auf standardisierte Explorer. Das reduziert die Schritte zwischen Erkennung und Behebung, senkt die kognitive Belastung in kritischen Momenten und gibt Teams mehr Zeit für das Wesentliche.
Ausblick
Wir sind weit gekommen – von statischen PNG-Grafiken und manueller Log-Suche hin zu einer Plattform, auf der Metrics Explorer und Logs Explorer täglich Terabytes an Daten verarbeiten. Kunden erhalten intuitive Werkzeuge zur Fehlersuche, und Engineers profitieren von einer gemeinsamen Innovationsplattform.
Als Nächstes stehen KI-gestützte Analysen sowie noch tiefere serviceübergreifende Integrationen an, um besser mit hochvolumigen Daten mit hoher Kardinalität umzugehen. Die Mission bleibt dabei unverändert: Kunden und Mission Control die Klarheit zu geben, die sie benötigen, um Netzwerke sicher, resilient und offen zu betreiben.



Lassen Sie die Komplexität
hinter sich
Sie möchten auch von der Open Systems SASE Experience profitieren? Unsere Experten helfen Ihnen gern weiter.
Kontakt